Google云計算三大核心技術 分布式數據處理MapReduce及其數據處理與存儲服務
隨著互聯網數據量的爆炸式增長,傳統的計算架構已難以應對海量數據的處理需求。在此背景下,Google作為云計算領域的先驅,提出并實踐了多項開創性的技術,其中分布式數據處理MapReduce、數據處理與存儲服務構成了其早期云計算核心技術體系的重要組成部分,為現代云計算和大數據處理奠定了堅實的基礎。
1. 分布式數據處理MapReduce:海量計算的革命性框架
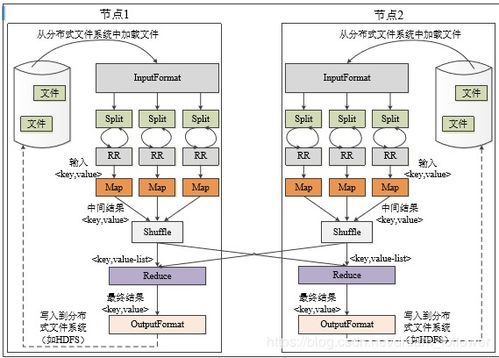
MapReduce是一種編程模型和相關的實現,用于大規模數據集(通常大于1TB)的并行計算。其核心思想源于函數式編程中的Map(映射)和Reduce(歸約)操作,旨在簡化分布式計算的復雜性,使開發者無需關注底層的任務調度、容錯、數據分發等繁瑣細節。
核心工作原理分為兩個階段:
1. Map(映射)階段: 用戶自定義一個Map函數,該函數處理輸入的鍵值對,生成一組中間鍵值對。計算框架將輸入數據自動分割成多個片段,并在大量計算節點上并行執行Map任務。
2. Reduce(歸約)階段: 用戶自定義一個Reduce函數,該函數接收Map階段輸出的、具有相同“中間鍵”的所有“中間值”,并對它們進行合并、匯總或其他處理,最終生成最終的輸出結果。框架會自動對中間結果進行排序和分發。
技術優勢與影響:
- 高可擴展性: 通過增加普通商用服務器節點即可線性擴展計算能力,輕松處理PB級數據。
- 高容錯性: 自動檢測失敗節點,并將失敗節點上的計算任務重新調度到其他健康節點執行。
- 簡化編程: 開發者只需關注業務邏輯(Map和Reduce函數),分布式系統的復雜性由框架處理。
MapReduce的開源實現Hadoop極大地推動了大數據產業的興起,成為了大數據處理的代名詞之一。
2. 數據處理與存儲服務:GFS與Bigtable
MapReduce的高效運行離不開底層強大的數據存儲與管理系統的支持。Google為此配套開發了另外兩大核心技術。
A. 分布式文件系統GFS
GFS是專門為大規模、高并發訪問和存儲超大規模文件而設計的分布式文件系統。它運行在廉價的商用硬件集群上,提供了高可靠性、高可用性和高吞吐量的數據存儲服務,是MapReduce的數據存儲基石。
核心特點:
- 主從架構: 包含一個主服務器(Master)和多個塊服務器(Chunk Server)。Master管理元數據,而實際的文件數據被分割成固定大小的“塊”,分散存儲在多個塊服務器上。
- 高容錯: 每個數據塊默認會在三個不同的服務器上創建副本,確保硬件故障時數據不丟失、服務不間斷。
- 為大文件優化: 針對搜索引擎場景下的大文件(如網頁存檔)進行優化,支持流式讀取和追加寫入。
B. 分布式結構化數據存儲系統Bigtable
Bigtable是一個用于管理結構化數據的分布式存儲系統,它被設計用來處理海量數據(PB級別),適用于從URL、網頁內容到用戶數據等多種Google服務。
核心特點:
- 稀疏的、分布式的、持久化的多維排序映射: 數據模型可以簡單理解為一種“鍵值”存儲,但其鍵是多維的(行鍵、列族、列限定符、時間戳),允許非常靈活和高效的數據布局。
- 高性能與高可擴展性: 數據按行鍵的字典序分片存儲,支持動態增刪節點以擴展容量和性能。
- 廣泛適用性: 既支持低延遲的隨機讀寫,也支持高效率的批量掃描,滿足了從實時查詢到批量處理的不同需求。
Bigtable的設計思想深刻影響了后續的NoSQL數據庫,如HBase、Cassandra等。
三大技術的協同關系
GFS、MapReduce和Bigtable并非孤立存在,而是構成了一個協同工作的強大技術棧:
- GFS 作為底層存儲,為MapReduce提供海量原始數據的持久化存儲和高吞吐訪問能力。
- MapReduce 作為計算引擎,可以高效地處理存儲在GFS或Bigtable中的海量數據,進行復雜的批量計算和分析。
- Bigtable 作為結構化的存儲服務,為需要快速隨機訪問和靈活數據模型的應用(如Web索引、Google Earth)提供支持,其本身也常作為MapReduce作業的輸入源或輸出目標。
與演進
Google提出的這三大核心技術(GFS, MapReduce, Bigtable)公開發表于2003至2006年的學術論文中,它們共同勾勒出了早期云計算基礎設施的藍圖。它們解決了在超大規模集群上存儲與計算的核心難題,即如何用廉價的商用硬件構建可靠、可擴展、高性能的系統。
盡管如今Google內部的技術棧已經迭代更新(例如用Colossus取代GFS,用Flume、MillWheel、Dataflow等更先進的模型補充或取代經典的MapReduce),但這些開創性的思想和技術設計原則——如分布式、容錯、自動分片、簡單編程模型——已經深深植根于現代云計算和大數據生態系統中,持續驅動著技術的發展。理解這三大核心技術,是理解當今云計算、大數據處理基石的關鍵一步。
如若轉載,請注明出處:http://www.qjnpl.cn/product/74.html
更新時間:2026-04-24 20:36:39