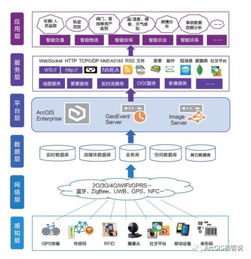
Apache Hive 3 中實(shí)現(xiàn)跨數(shù)據(jù)庫(kù)聯(lián)邦查詢的條件查詢語(yǔ)句與數(shù)據(jù)處理服務(wù)
在大數(shù)據(jù)生態(tài)系統(tǒng)中,Apache Hive 作為基于 Hadoop 的數(shù)據(jù)倉(cāng)庫(kù)工具,以其強(qiáng)大的 SQL 查詢能力(HiveQL)而廣為人知。隨著數(shù)據(jù)源的多樣化和數(shù)據(jù)孤島問(wèn)題的凸顯,能夠跨不同數(shù)據(jù)庫(kù)或數(shù)據(jù)存儲(chǔ)系統(tǒng)進(jìn)行查詢的需求日益增長(zhǎng)。Apache Hive 3 通過(guò)其增強(qiáng)的聯(lián)邦查詢(Query Federation)能力,為這一挑戰(zhàn)提供了解決方案。本文將重點(diǎn)介紹在 Hive 3 中如何結(jié)合條件查詢語(yǔ)句,實(shí)現(xiàn)跨數(shù)據(jù)庫(kù)的聯(lián)邦查詢,并闡述其在數(shù)據(jù)處理和存儲(chǔ)服務(wù)中的角色。
一、 Hive 條件查詢語(yǔ)句基礎(chǔ)
在深入聯(lián)邦查詢之前,首先需要理解 Hive 的核心——HiveQL 條件查詢。條件查詢主要通過(guò) WHERE、HAVING、CASE WHEN 等子句實(shí)現(xiàn)數(shù)據(jù)篩選。
1. WHERE 子句:用于從表中篩選滿足指定條件的行。
`sql
SELECT * FROM sales WHERE amount > 1000 AND region = 'North';
`
此查詢從 sales 表中選取金額大于1000且地區(qū)為“North”的所有記錄。
2. HAVING 子句:通常與 GROUP BY 一起使用,用于對(duì)分組后的結(jié)果進(jìn)行條件過(guò)濾。
`sql
SELECT region, SUM(amount) AS total_sales
FROM sales
GROUP BY region
HAVING SUM(amount) > 50000;
`
此查詢計(jì)算每個(gè)地區(qū)的總銷(xiāo)售額,并僅返回總銷(xiāo)售額超過(guò)50000的地區(qū)。
3. CASE WHEN 表達(dá)式:提供條件邏輯,可用于 SELECT 列表、WHERE 子句等位置,實(shí)現(xiàn)復(fù)雜的條件分支。
`sql
SELECT orderid, amount,
CASE
WHEN amount > 1000 THEN 'High Value'
WHEN amount BETWEEN 500 AND 1000 THEN 'Medium Value'
ELSE 'Low Value'
END AS valuecategory
FROM orders;
`
這些基礎(chǔ)的條件查詢能力是構(gòu)建更復(fù)雜查詢的基石。
二、 Apache Hive 3 的聯(lián)邦查詢(Query Federation)
Hive 3 引入了對(duì)聯(lián)邦查詢的顯著支持,通過(guò) Hive Storage Handlers 和 HCatalog 的集成,能夠?qū)⒉樵兺该鞯胤职l(fā)到不同的外部數(shù)據(jù)源,如關(guān)系型數(shù)據(jù)庫(kù)(MySQL, PostgreSQL)、NoSQL 數(shù)據(jù)庫(kù)(HBase)、云存儲(chǔ)服務(wù)(AWS S3, ADLS)等。核心思想是:Hive 作為查詢引擎和協(xié)調(diào)者,而實(shí)際的數(shù)據(jù)存儲(chǔ)和部分計(jì)算可能下推到外部數(shù)據(jù)源執(zhí)行。
關(guān)鍵組件與步驟:
- 創(chuàng)建外部表(External Table):需要為遠(yuǎn)程數(shù)據(jù)源創(chuàng)建一個(gè) Hive 外部表,該表不存儲(chǔ)數(shù)據(jù),只存儲(chǔ)元數(shù)據(jù)(如表結(jié)構(gòu))和指向遠(yuǎn)程數(shù)據(jù)源的連接信息。這通常通過(guò)
STORED BY子句指定特定的存儲(chǔ)處理器(Storage Handler)來(lái)實(shí)現(xiàn)。
- 配置數(shù)據(jù)源連接:在創(chuàng)建表時(shí)或通過(guò)配置,需要提供訪問(wèn)外部數(shù)據(jù)源的 JDBC 驅(qū)動(dòng)、連接URL、用戶名、密碼等信息。
- 透明查詢:創(chuàng)建成功后,即可像查詢普通 Hive 表一樣,使用 HiveQL(包括條件查詢語(yǔ)句)對(duì)這個(gè)外部表進(jìn)行查詢。Hive 會(huì)嘗試將盡可能多的操作(如過(guò)濾、投影)下推到外部數(shù)據(jù)源執(zhí)行,以減少數(shù)據(jù)傳輸量,提高查詢效率。
三、 結(jié)合條件查詢實(shí)現(xiàn)跨數(shù)據(jù)庫(kù)聯(lián)邦查詢
假設(shè)我們有一個(gè)本地 Hive 表 local<em>employees(存儲(chǔ)在 HDFS)和一個(gè)遠(yuǎn)程 MySQL 數(shù)據(jù)庫(kù)中的表 remote</em>departments。我們想查詢“North”區(qū)域薪資高于80000的員工及其部門(mén)信息。
步驟示例:
1. 為 MySQL 表創(chuàng)建 Hive 外部表:
`sql
CREATE EXTERNAL TABLE federateddepartments (
deptid INT,
deptname STRING,
region STRING
)
STORED BY 'org.apache.hive.storage.jdbc.JdbcStorageHandler'
TBLPROPERTIES (
"hive.sql.database.type"="MYSQL",
"hive.sql.jdbc.driver"="com.mysql.cj.jdbc.Driver",
"hive.sql.jdbc.url"="jdbc:mysql://mysql-host:3306/companydb",
"hive.sql.jdbc.username"="yourusername",
"hive.sql.jdbc.password"="yourpassword",
"hive.sql.query"="SELECT deptid, deptname, region FROM departments" -- 可指定遠(yuǎn)程表或查詢
);
`
2. 執(zhí)行跨庫(kù)條件連接查詢:
`sql
SELECT e.empname, e.salary, d.deptname
FROM localemployees e
JOIN federateddepartments d ON e.deptid = d.deptid
WHERE e.region = 'North'
AND e.salary > 80000
AND d.region = 'North'; -- 條件同時(shí)應(yīng)用于本地表和遠(yuǎn)程聯(lián)邦表
`
執(zhí)行過(guò)程:
- Hive 解析該查詢,識(shí)別出
federated_departments是一個(gè)聯(lián)邦表。
- 對(duì)于
WHERE子句中涉及聯(lián)邦表的條件(d.region = 'North'),Hive 會(huì)通過(guò) JDBC 存儲(chǔ)處理器,嘗試將其與連接條件一起“下推”到 MySQL 數(shù)據(jù)庫(kù)執(zhí)行。理想情況下,Hive 會(huì)向 MySQL 發(fā)送一個(gè)查詢,類(lèi)似于:SELECT dept<em>id, dept</em>name FROM departments WHERE region = 'North'。
- 本地條件(
e.region = 'North' AND e.salary > 80000)在 Hive 端對(duì)local_employees表進(jìn)行過(guò)濾。
- Hive 將兩邊過(guò)濾后的結(jié)果在內(nèi)存或集群中進(jìn)行連接操作。
四、 在數(shù)據(jù)處理和存儲(chǔ)服務(wù)中的角色與優(yōu)勢(shì)
將 Hive 3 的聯(lián)邦查詢與條件查詢結(jié)合,可以在現(xiàn)代數(shù)據(jù)架構(gòu)中扮演強(qiáng)大的“數(shù)據(jù)虛擬化”或“查詢聯(lián)邦層”角色:
- 統(tǒng)一查詢?nèi)肟?/strong>:為數(shù)據(jù)分析師和數(shù)據(jù)科學(xué)家提供統(tǒng)一的 SQL 接口(HiveQL),無(wú)需學(xué)習(xí)多種查詢語(yǔ)言或直接連接多個(gè)數(shù)據(jù)源,即可訪問(wèn)分散的數(shù)據(jù)。
- 邏輯數(shù)據(jù)倉(cāng)庫(kù):在不進(jìn)行大規(guī)模物理數(shù)據(jù)遷移(ETL)的前提下,整合來(lái)自操作型數(shù)據(jù)庫(kù)(OLTP)、數(shù)據(jù)湖、數(shù)據(jù)倉(cāng)庫(kù)等不同系統(tǒng)的數(shù)據(jù),進(jìn)行關(guān)聯(lián)分析和即席查詢。
- 下推優(yōu)化提升性能:通過(guò)將條件過(guò)濾、列投影等操作下推到源數(shù)據(jù)庫(kù)執(zhí)行,僅將所需的結(jié)果集拉取到 Hive,極大減少了網(wǎng)絡(luò)傳輸和 Hive 端的處理負(fù)載,提升了查詢性能。
- 簡(jiǎn)化數(shù)據(jù)管道:在某些場(chǎng)景下,可以減少為了數(shù)據(jù)整合而設(shè)計(jì)的復(fù)雜 ETL 流程,實(shí)現(xiàn)更靈活、實(shí)時(shí)的數(shù)據(jù)訪問(wèn)模式。
- 與現(xiàn)有存儲(chǔ)服務(wù)集成:除了傳統(tǒng)數(shù)據(jù)庫(kù),Hive 聯(lián)邦查詢也支持對(duì)象存儲(chǔ)(如 S3)、文檔數(shù)據(jù)庫(kù)等,使其能夠成為混合云、多存儲(chǔ)環(huán)境下數(shù)據(jù)訪問(wèn)的統(tǒng)一服務(wù)層。
挑戰(zhàn)與注意事項(xiàng):
- 性能依賴:查詢性能很大程度上受制于最慢的外部數(shù)據(jù)源和網(wǎng)絡(luò)延遲。
- 功能限制:并非所有 HiveQL 函數(shù)和優(yōu)化都能下推到所有數(shù)據(jù)源。需要根據(jù)具體的存儲(chǔ)處理器和數(shù)據(jù)源能力進(jìn)行評(píng)估。
- 安全與權(quán)限:需要妥善管理多個(gè)數(shù)據(jù)源的連接憑證和訪問(wèn)權(quán)限。
結(jié)論
Apache Hive 3 的聯(lián)邦查詢功能,結(jié)合其強(qiáng)大的 HiveQL 條件查詢語(yǔ)句,為構(gòu)建跨數(shù)據(jù)庫(kù)、跨存儲(chǔ)系統(tǒng)的數(shù)據(jù)查詢服務(wù)提供了強(qiáng)大支持。它允許組織在不擾動(dòng)現(xiàn)有數(shù)據(jù)存儲(chǔ)布局的前提下,實(shí)現(xiàn)數(shù)據(jù)的邏輯整合與聯(lián)合分析,是現(xiàn)代數(shù)據(jù)湖倉(cāng)一體、數(shù)據(jù)虛擬化架構(gòu)中的關(guān)鍵組件之一。成功實(shí)施的關(guān)鍵在于深入理解外部數(shù)據(jù)源的特性和 Hive 存儲(chǔ)處理器的能力,并合理設(shè)計(jì)查詢,以最大化利用下推優(yōu)化,從而構(gòu)建高效、靈活的數(shù)據(jù)處理與存儲(chǔ)服務(wù)。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://www.qjnpl.cn/product/55.html
更新時(shí)間:2026-03-07 15:48:07