健腹器,作為強化核心肌群、塑造腹部線條的健身利器,種類繁多,功能各異。本文將為您呈現一份健腹器AB圖片大全,并結合常見類型,解析其特點與使用方法。
一、 常見健腹器類型圖鑒
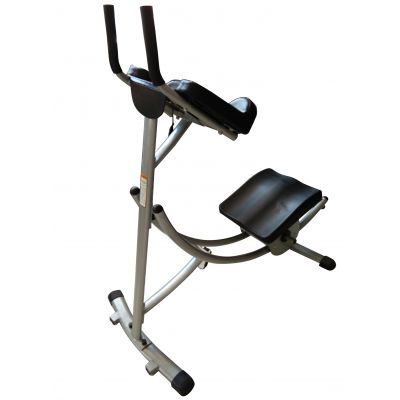
- 仰臥起坐板/健腹板: 這是最經典的器械之一。圖片通常展示一個帶有角度調節和固定腳架的板床。使用者仰臥其上,通過調節角度(越陡越難)進行卷腹或仰臥起坐,能有效減少頸部與腰部代償,精準刺激腹直肌。
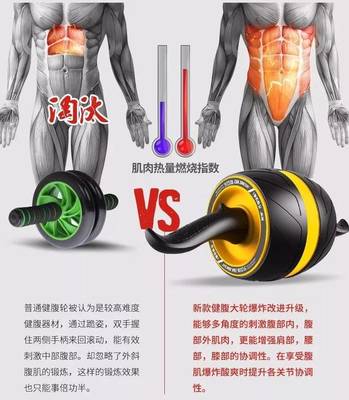
- 健腹輪: 圖片中多為一個帶雙手握把的小輪。使用時跪姿(或站姿)手持握把,向前滾動身體至極限,再依靠腹部力量收縮回拉。它對腹橫肌、腹直肌乃至全身核心穩定性要求極高,是進階訓練者的選擇。
- 扭腰盤/健腹盤: 圖片上通常是一個可旋轉的圓形踏板。使用者站立或跪立于上,通過腰部發力帶動身體左右旋轉。它主要鍛煉腹斜肌,幫助塑造腰部曲線,動作相對和緩。
- 懸掛式健腹器(如TRX): 圖片展示通過懸掛帶,利用自身重量進行訓練。例如懸掛舉腿、懸掛卷腹等動作,能多角度、高強度地刺激整個核心區域,對穩定性提升顯著。
- 電動健腹儀/EMS肌肉刺激器: 這類產品圖片常顯示為帶有電極片的腰帶或貼片。它通過微電流模擬大腦信號,被動促使肌肉收縮。需注意,其主要用于輔助塑形或放松,不能替代主動運動帶來的健康效益。
二、 如何選擇與高效使用
- 根據水平選擇: 新手建議從仰臥起坐板或扭腰盤開始,掌握發力感;有基礎者可嘗試健腹輪或懸掛訓練。
- 動作質量至上: 觀看正確動作圖片或視頻,確保用腹部發力,避免用脖子或腰部蠻力。寧慢勿快,感受肌肉收縮。
- 結合全面訓練: 單純依賴健腹器難以顯現“馬甲線”或“腹肌”,必須配合有氧運動降低體脂,并結合全身力量訓練。
- 持之以恒: 腹部肌群恢復較快,可隔天訓練,每次選擇1-2種器械,多角度刺激,每組動作做至力竭邊緣。
三、 安全提示
使用前檢查器械穩定性;飯后一小時再訓練;腰椎不適者應避免大幅卷曲動作,可先咨詢醫生或教練。
通過健腹器AB圖片大全,我們能直觀了解器械形態。選擇適合自己的器械,掌握正確方法并堅持鍛煉,才是打造健康、強壯核心區域的根本之道。